
Aegis School of Business, Data Science, Cyber Security & Telecommunication
| Application fee: | 1000 * INR |
| Course fee: | 45000 * INR |
| GST: | 18 % |
Machine Learning at Scale with Spark ML

Details
| Certification Body: | Aegis School of Data Science |
|---|---|
| Location: | On-campus (India, ) |
| Type: | Certificate course |
| Coordinator: | Ritin Joshi |
| Language: | English |
| Course fee: | 45000 * INR |
| GST: | 18% |
| Total course fee: | 53100 * INR |
| Rating: |
Gallery

Course Details
This course deals at how to do Machine Learning at a large scale, involving terabytes (may be even petabytes) of data and across several server nodes. The best answer is Apache Spark ML (MLlib)!
What is Spark?
Apache Spark™ is a fast and general engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Spark is an in-memory analytics engine which runs on top of HDFS and also unifies many other data sources e.g. NoSQL databases like MongoDB or even CSV files. Spark is also a much faster and simpler replacement of Hadoop's original processing model - MapReduce. IBM has announced plans to include Spark in all its analytics platforms and has committed 3,500+ developers to Spark-related projects.
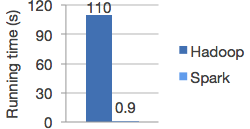
Speed
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Apache Spark has an advanced DAG execution engine that supports acyclic data flow and in-memory computing.
Ease of Use
Write applications quickly in Java, Scala, Python, R.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells.
text_file.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a+b)
Generality
Combine SQL, streaming, and complex analytics.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.

Runs Everywhere
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, or on Apache Mesos. Access data in HDFS, Cassandra, HBase, Hive, Tachyon, and any Hadoop data source.

What is Spark MLlib?
MLlib is Spark’s machine learning (ML) library. Its goal is to make practical machine learning scalable and easy. At a high level, it provides tools such as:
- ML Algorithms: common learning algorithms such as classification, regression, clustering, and collaborative filtering
- Featurization: feature extraction, transformation, dimensionality reduction, and selection
- Pipelines: tools for constructing, evaluating, and tuning ML Pipelines
- Persistence: saving and load algorithms, models, and Pipelines
- Utilities: linear algebra, statistics, data handling, etc.
What will be covered this course?
-
1. Basics
- Sub-Topic
- Why SPARK?
- What does it mean to learn SPARK?
- SPARK Basics
- Installation
- SCALA: An Introduction
- The SPARK Context
- Introduction to RDDs
- RDDs: Creation / Transformation / Actions
- Exercises and applications
2. Dataframes, Datasets, SQL SPARK Streaming
- Introduction
- The SQL Context
- Data I/O
- Transformations and Actions
- Concepts and elements of Streaming
- Working with SPARK Streaming
- Exercises and applications
3. SPARK Mlib SPARK GraphX
- Basics of Mlib
- Statistics using Mlib
- Machine Learning using Mlib
- Basics of Graph Processing
- GraphX RDDs
- Applications of GraphX
- Exercises and applications
4. Case studies, applications Project Discussions
- Case studies, applications
- Project Discussions
- SPARK resources
- Trends
5. Final Project